
In the vast and complex world of cyberspace, vulnerable communities often find themselves at the mercy of threat actors, necessitating the urgent need for organizations dedicated to protecting communities from these threats. The CyberPeace Institute is an independent nonprofit organization whose mission is to ensure the rights of people to security, dignity, and equity in cyberspace. Its team of experts provides support and free practical cyber assistance to humanitarian NGOs across the world. One vital aspect of our work involves cyber threat intelligence and analysis, which is crucial for identifying, monitoring, and combating cyber threats.

To conduct effective analyses, our team recognises the importance of leveraging unstructured data, which can include a wide range of non-standardised sources of information, including articles and reports in different formats such as HTML/PDF, etc. The manual processing of such sources, while highly valuable, poses several challenges. Firstly, the sheer volume of data available in different formats and from various sources makes it impractical for analysts to efficiently process and extract meaningful insights within a reasonable timeframe. Furthermore, unstructured data is often fragmented and lacks a coherent structure, making it challenging to extract relevant information and identify trends or patterns. Overall, manual analysis of unstructured data is not only time-consuming and labor-intensive but also prone to inconsistencies.
To develop and strengthen our data processing techniques, the CyberPeace Institute joined the 2023 Data Practice Accelerator Program organized by the Patrick J. McGovern Foundation. This program is designed to support nonprofit organizations in their data journeys by offering mentorship, tools, and expertise needed to refine approaches to data handling.

A strategy for processing unstructured data is through the implementation of machine learning. By leveraging advanced algorithms and techniques, machine learning models can automatically process vast amounts of data, extracting valuable insights at an unprecedented scale. Integrating machine learning into our analysis processes will empower analysts, enabling them to streamline their work, identify patterns more effectively, and respond promptly to emerging threats.
In the following segment of this article, we detail the CyberPeace Institute’s efforts to automate the analysis of unstructured data, harnessing the power of machine learning.
Machine learning pipeline at the CPI
Overview
The pipeline components
- Storage:
A storage system where the original files reside. - Data Extraction:
Text extraction / cleanup of the original files, removing irrelevant data. - Named Entity Recognition:
Use of machine learning models to extract relevant entities, such as named individuals and organizations. - Output:
A collaborative platform for analysts to interact, give feedback and utilize the generated output.
Data Extraction
The data extraction process posed significant challenges, specifically in the extraction of text from unstructured PDF documents. This matter can be further segmented into various subproblems, including the detection of images and tables within the documents, filtering out headers and footers, and effectively handling both single-column and multi-column pages.
Initially, we started by using Google’s Optical Character Recognition (OCR) technology to extract text from PDF documents. Google’s OCR model was very successful at extracting the text within the documents but failed to return context about the extracted text. For example, Google OCR detected and extracted text within images and tables. However, the extracted text wasn’t contextually harmonious with the document, and it was not possible to separate those blocks from the remaining content.
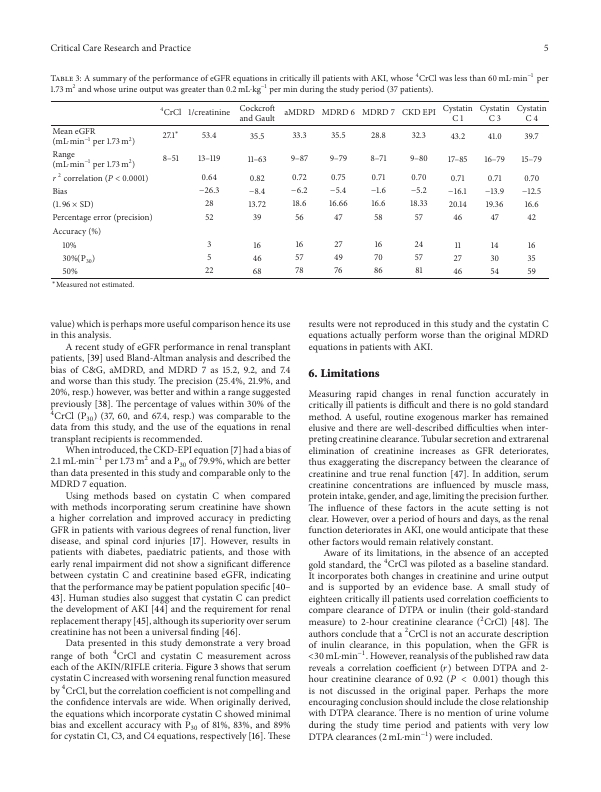
Next, we used an open-source package called “Parsr” that was able to classify images and tables and return text with context. The Parsr package carried all of the functionalities that we wanted, but the overall performance of the package was poor in detecting tables in documents and extracting text from multi-column page layouts. One of the biggest problems in table detection was that the package wasn’t able to detect borderless or semi-structured tables inside the PDFs and thus was parsing those types of tables as part of the general text.

Example of a borderless table

Example of a semi-structured table
Our current methodology employs a combination of various techniques to achieve the extraction of refined text. In the realm of table detection, we currently employ a fine-tuned Detection Transformer (DETR) model capable of detecting both bordered and borderless tables. To extract the headers and footers from the text, we utilize Parsr’s modules, which leverage computer vision techniques to identify the headers and footers within the documents. In addition to these data-cleaning procedures, we perform standard text-cleaning operations to address any Unicode characters / Diacritics within the paragraphs, eliminate non-ASCII characters, and segment the text into sentences to facilitate subsequent analysis.
In our ongoing development of the machine learning pipeline, we are conducting experiments with the integration of Document Image Transformers (DiT) to enhance the effectiveness of our existing DETR model. At present, we have encountered certain false positive detections when employing the DiT model in a multi-column layout. Consequently, we believe that performing a comprehensive layout analysis of the documents, rather than solely focusing on table detection, will yield improved outcomes.
Document Layout Analysis with DiT
As part of our upcoming advancements in the machine learning pipeline, we aim to incorporate a process enabling the extraction of unrelated text segments within the documents. These segments typically encompass article recommendations sourced from the internet, advertisements, and other forms of unrelated textual data. By implementing this capability, we seek to enhance the precision and accuracy of the information extracted, ensuring that only relevant and meaningful content is considered for further analysis and processing. In order to achieve this goal, we have engaged in discussions with data scientists on PJMF’s Data Practice team to explore potential ideas and examine the feasibility of implementing an outlier detection pipeline utilizing text embeddings.



Examples of outlier text in documents
Named Entity Recognition
In the initial phase of our machine learning pipeline, we have integrated a Named Entity Recognition (NER) tool as our first analysis component. Our primary focus has been on extracting person and organization names from documents. To fulfill this objective, we initially employed the NLP AI from the Google Cloud Platform. However, we encountered limitations with the Google API, as it also extracted plain nouns alongside person and organization names, which was not suitable for our specific requirements.
To address this issue, we introduced a large BERT model that underwent fine-tuning specifically for NER tasks involving names and organizations. We observed that the BERT model outperformed its NLP AI counterpart in this regard. However, recognizing that the NLP AI API still exhibited proficiency in identifying entities such as addresses, locations, and numbers, we made the decision to retain this model within our pipeline as well.
In our collaborative brainstorming sessions with PJMF data scientists, we have touched on the potential of using BERT models that have been specifically fine-tuned on cybersecurity data. We discussed how incorporating these models could enhance our Named Entity Recognition (NER) performance. Moving forward, it would be valuable to conduct experiments with these domain-specific models as potential replacements for our current BERT model.

Person extraction by Bert
In the upcoming project phases, we have outlined plans to develop a custom NER model. This customized model will enable us to identify and classify specific entities that we define according to our requirements. By training this tailored NER model, we aim to enhance the accuracy and effectiveness of entity identification for our project.
Pipeline Implementation / Stages
At the Institute, our piping system of choice is Airflow which is running in a Kubernetes cluster.
Using Airflow and the functionalities mentioned earlier, we have successfully completed a minimum viable product and are currently in the process of building a more sophisticated and elaborate second version of the product, where we are enhancing the performance of the pipeline.
During the initial phase of the pipeline, users are required to provide the precise location of the document they wish to process within Google Cloud Storage. Once specified, the pipeline retrieves the document and directs it through a preprocessing flow that varies based on the file type. In the initial version, support is provided for PDF, HTML, and TXT file formats. For HTML and TXT files, the text within the document is obtained after being cleaned. However, for PDF files, additional steps are involved, including OCR, extraction of headers and footers, and detection of tables. These modules ensure accurate processing and extraction of relevant information from PDF documents. Once the text preparation steps have been executed, the sanitized text is then input into the NER models for further analysis. The NER models identify and classify entities within the text. Subsequently, the resulting entity extraction outputs are stored back in a bucket for future accessibility.
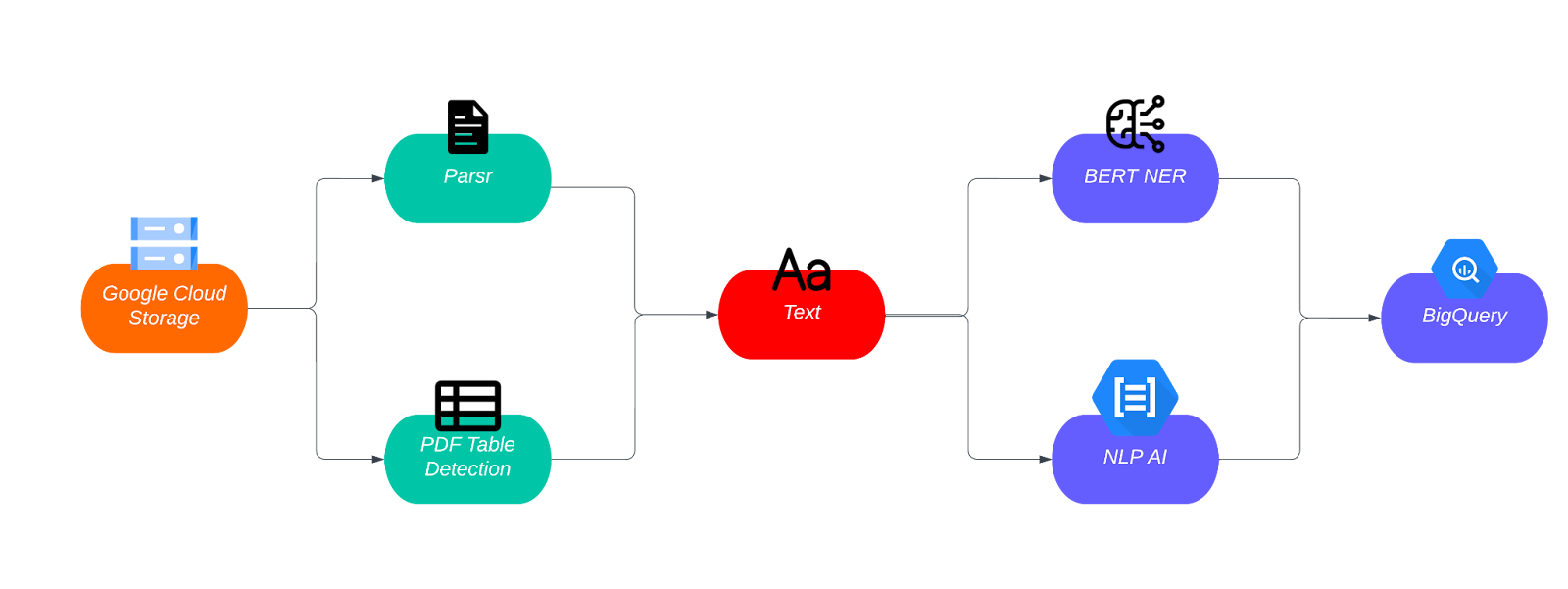
Pipeline for PDF files
During the implementation of the initial version, a significant challenge we encountered was the deployment of the machine learning (ML) models within the pipeline. Initially, we pursued a strategy of deploying these models on a Kubernetes cluster by containerizing them with Docker. While we were successful in deploying the models on the clusters, we faced difficulties in managing and maintaining these resource-intensive clusters. It became evident that this approach might not be the most optimal solution for running and sustaining the models in the long term.
After exchanging ideas with PJMF’s Data Practice team, we made the decision to leverage Google’s Vertex AI for deploying our ML models to address the challenges encountered. Vertex AI utilizes Google Cloud’s robust infrastructure to offer scalable and high-performance computing resources, eliminating our resource constraints during deployment. Additionally, it enables comprehensive management of the entire ML lifecycle and integrates well with our existing Google-based infrastructure.
As the first step, we began by utilizing Vertex AI endpoints, which host the ML models and provide constant accessibility. By making API calls, users can send prediction requests to the model and receive prompt results. However, endpoints have limitations, such as restricting the model’s runtime to under one minute. This limitation poses a challenge for prediction requests that require more time and can also impact cost efficiency. Considering these factors, we have opted to utilize Batch predictions instead.
Batch predictions allow us to process multiple files for prediction simultaneously and do not impose any runtime limits on the models. However, it is important to note that the initial setup for running batch predictions is more time-consuming compared to endpoints, and the results take longer to be returned. Despite this drawback, batch predictions provide a more suitable solution for our requirements due to their flexibility, absence of runtime restrictions, and the ability to process multiple files at once. To further improve the runtime performance, we implemented the utilization of GPUs for the ML models. This achieved a 10x speedup in processing time.
In the second and current iteration of the pipeline, we focused on automating the initialization process. This automation involved using Google’s Cloud Storage Triggers and Pub/Sub to store all document creation events for our storage bucket in a publisher. From there, a periodically run operation in Airflow is run, and if new data are detected, it triggers the appropriate pipeline to process these files accordingly based on their type. Another notable advancement in the pipeline is the introduction of batch processing. Instead of processing files individually, we have implemented a mechanism to handle files in batches. This approach allows us to leverage the benefits of batch predictions, reducing the overall time consumed per file.
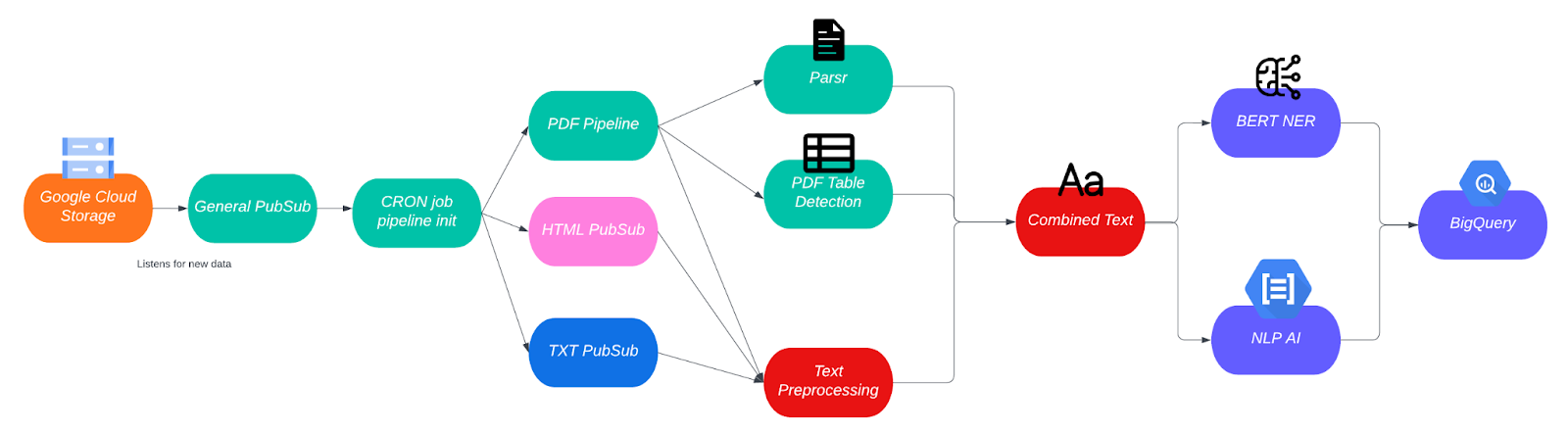
Pipeline Version II
Next Steps
The CyberPeace Institute’s machine learning pipeline will undergo further enhancements and expansions to improve the efficiency and effectiveness of data processing and analysis. We intend to concentrate our efforts on the following key areas:
- Improve Table Detection.
- Identify and remove irrelevant text segments from the original files.
- Train a Custom (NER) Model.
- Integrate a Domain-Specific BERT Models.
- Continue refining the Airflow pipeline.
- Finalize a user interface (UI) designed to visually display the pipeline output.
By focusing on these next steps, we aim to optimize our machine learning pipeline, enabling more efficient analysis of unstructured data and empowering analysts to identify cyber threats, patterns, and trends more effectively. These advancements will contribute to the institute’s mission of ensuring security, dignity, and equity in cyberspace for vulnerable communities.
Visit here to learn more.